In der agilen Welt gibt es viele Missverständnisse über SAFe®, insbesondere über die Schätzung mit Story Points. Das führt dazu, dass schlechte Praktiken unkorrigiert bleiben und ständig wiederholt werden. Tauche ein in eine Erkundung, die gängige Vorstellungen über die Schätzung in SAFe in Frage stellt und das wahre Wesen der Story Points aufdeckt. Ganz gleich, ob du gerade erst deinen Weg in SAFe beginnst oder meinst, bereits alles über dieses Framework zu wissen, dieser Beitrag wird dir neue Einsichten bieten. Wenn du einen fundierten Einblick in die korrekte Anwendung agiler Schätzmethoden gewinnen möchtest – die sich über Jahre bewährt haben und unverändert in SAFe genutzt werden – dann lies diesen Artikel.
TLDR: Wenn wir SAFe® verwenden, ändern wir nicht die Art und Weise, wie wir Story Points und Schätzungen verwenden. Wir fügen nur eine weitere Ebene hinzu. Diese folgt jedoch den gleichen Prinzipien.
- Gute SAFe-Implementierungen, insbesondere die Schätzung, bauen auf langjährige agile Erfahrungen auf.
- In SAFe fließen Produkt-Backlog-Einträge auf verschiedenen Ebenen. Dieser Artikel befasst sich zunächst mit den Team Backlogs und dann mit dem Team-of-Teams (ART) Backlog.
- Nein, in SAFe messen wir keine normalisierten Story Points auf der Grundlage von “ideal developer days”. Das ist falsch, und wenn das gemacht wird, ist das ein Problem.
- Wir schätzen die Größe von Product Backlog Einträgen im Verhältnis zu anderen Einträgen.
- Bevor wir anfangen, mit Story Points zu schätzen, müssen wir definieren, was “1” bedeutet.
- Es hilft, wenn Teams, die zusammenarbeiten, ein gemeinsames Verständnis von Größe haben, aber es ist nicht notwendig.
- Nachdem wir mit einer Definition von “1” mit der Schätzung begonnen haben, werden alle geschätzten Product Backlog Einträge zu Referenzpunkten für weitere relative Schätzungen.
- Wir messen Velocity und prognostizieren Kapazität.
- Nur bei einem neuen Team berechnen (“raten”) wir die anfängliche Kapazität.
- Mit den Story Points und der Velocity können wir Liefertermine prognostizieren.
- Story Points sind nicht für Vergleiche oder Vergütung gedacht.
- Ein Team kann nicht aufhören, Story Points mit dem Aufwand in Verbindung zu bringen? Verwende T-Shirt-Größen.
- Features können ihre eigene relative Größe haben.
Gute SAFe®-Implementierungen, insbesondere die Schätzung, bauen auf langjährige agile Erfahrungen auf.
Was mir an SAFe gefällt, ist, dass es bestehende agile Frameworks und Methoden zusammenführt. So können wir bei der Umsetzung von SAFe auf eine lange Historie an agilen Erfahrungen aufbauen. Das gilt insbesondere für die Schätzung in SAFe.
Deshalb schlage ich in diesem Blogartikel bewusst Brücken zwischen SAFe, Scrum und Kanban, was das Wissen und die Terminologie angeht. Ich tue dies aus drei Gründen.
- Eine gute SAFe-Implementierung ist den eingebetteten Frameworks treu.
- Es gibt eine Fülle von Wissen rund um die eingebetteten Frameworks, das uns hilft, gute SAFe-Implementierungen zu gestalten, in diesem Fall gute Schätzungen.
- Wir müssen Brücken bauen zwischen Menschen mit unterschiedlichem Hintergrund bei der Nutzung agiler Frameworks. In Anlehnung an das agile Manifest erfordert das Zusammenbringen von Individuen und ihren Interaktionen noch mehr Aufmerksamkeit als das Zusammenbringen der Frameworks.
In diesem Artikel möchte ich zeigen, wie diese Denkweise dazu beiträgt, gute Schätzverfahren in einer Multi-Team-Umgebung mit SAFe zu erreichen.
In SAFe® fließen Produkt-Backlog-Einträge auf verschiedenen Ebenen. Dieser Artikel befasst sich zunächst mit den Team Backlogs und dann mit dem Team-of-Teams (ART) Backlog.
Wenn wir in mehreren Teams arbeiten, haben wir in der Regel einen Fluss von Product Backlog Einträgen auf verschiedenen Ebenen.
SAFe verwendet Stories (die in einen Sprint/Iteration passen) und Features (die in eine größere Kadenz von mehreren Sprints/Iterationen passen, das Planungsintervall oder PI). In diesem Artikel werden wir uns zwei wesentliche Ebenen ansehen: Die Team Backlogs enthalten Stories, und das übergeordnete ART Backlog enthält Features. (ART ist ein Akronym für Agile Release Train, also ein Team von Teams.)
Das ART Product Backlog (Features) und die Team Product Backlogs (Stories) sind das, was Scrum das Product Backlog nennt. Das Verständnis dafür hilft dabei, das vorhandene Wissen über Schätzungen auf beide Ebenen anzuwenden. Wenn wir die Schätzung von Stories verstehen, verstehen wir auch die Schätzung von Features. Der Unterschied sollte nicht groß sein, denn beides sind Product Backlog-Einträge.
In diesem Artikel gehe ich zunächst auf die Story-Ebene der Team Backlogs ein. Dann werde ich das Gesagte auf die Feature-Ebene des ART Backlogs übertragen. Wenn etwas sowohl auf das ART Backlog als auch auf die Team Backlogs zutrifft, so spreche ich von einem Product Backlog ohne Bezug zu ART oder Team.
Nein, in SAFe® messen wir keine normalisierten Story Points auf der Grundlage von “ideal developer days”.
Viele Artikel behaupten, dass wir in SAFe normalisierte Story Points messen, die auf “ideal developer days” beruhen (z.B.. Kevin Bendeler). Ja, das tun viele Teams. Nein, das ist falsch – in vielerlei Hinsicht. Und es ist nicht das, was SAFe vorschlägt (siehe Iteration Planning und WSJF). SAFe ist nicht das Problem. Schauen wir uns also an, wie Schätzungen mit mehreren Teams funktionieren.
Wir schätzen die Größe von Product Backlog Einträgen im Verhältnis zu anderen Einträgen.
Die Zahl, die wir für die Größe eines Team Product Backlog Eintrags (“Story”) angeben, heißt “Story Point”. Story Points sind eine relative Schätzung. Das bedeutet, dass ein Eintrag mit 2 Story Points doppelt so groß ist wie ein Eintrag mit 1 Story Point, und ein Eintrag mit 8 Story Points ist achtmal so groß wie ein Eintrag mit der Größe 1 oder viermal so groß wie ein Eintrag mit Größe 2. Im Vergleich zu einer 1-SP-Story sollte eine 2-SP-Story etwa doppelt so viel Aufwand bei der Umsetzung benötigen.
Story Points Schätzungen sind relativ zueinander, aber Story Points haben keine feste Beziehung zu Aufwand (und das schließt Dinge wie “ideal developer days” ein). Der Grund für relative Schätzungen ist, dass sie uns die Zeit sparen, neu zu schätzen, wenn ein Team schneller wird. Außerdem können wir so Durchsatz nachvollziehen und Vorhersagen treffen – Dinge, die wir mit einer empirischen Denkweise gerne tun. Die Größe der Product Backlog Einträge wird von Entwicklern geschätzt.
Ein wichtiger Punkt bei einer Schätzung ist, dass es sich nicht um eine Zahl handelt, sondern um eine Wahrscheinlichkeitsverteilung um unseren Schätzwert herum. Wenn wir schätzen, dass ein Eintrag eine Größe von 2 hat, kann der tatsächliche Wert (sobald wir den Eintrag umgesetzt haben und die tatsächliche Größe kennen) alles Mögliche sein, aber eine 2 ist wahrscheinlicher als eine 13. Die Unsicherheit und Streuung der Verteilung nimmt mit größeren Schätzwerten zu. Deshalb wird die Spanne der Story Points mit zunehmender Größe immer größer (3, 5, 8, 13 …).
Bevor wir anfangen, mit Story Points zu schätzen, müssen wir definieren, was “1” bedeutet.
Als unabhängige Größeneinheit brauchen Story Points eine Definition dafür, was “1” bedeutet. Normalerweise wählen wir dazu eine Story, die wir als Referenz für die Größe “1” verwenden. SAFe schlägt vor, einen Team Product Backlog Eintrag zu wählen, der “einen halben Tag zur Entwicklung plus einen halben Tag zum Testen und Validieren” benötigt. Es kann nicht genug betont werden, dass dies nur ein Vorschlag ist, um eine Story der Größe “1” zu finden. Die Referenz ist die gefundene Story, nicht der Personentag und schon gar nicht ein “ideal developer day” (so etwas gibt es in SAFe nicht).
Wenn ihr eine andere Vorgehensweise bevorzugt, um die Story der Größe 1 zu finden, könnt ihr sie gerne verwenden. Teams können sich auf jede Methode einigen, um die “1” zu finden, solange sie eine Referenzstory ergibt.
Es hilft, wenn Teams, die zusammenarbeiten, ein gemeinsames Verständnis von Größe haben, aber es ist nicht notwendig.
Wenn ihr mehrere Teams habt, die gemeinsam an demselben Product Backlog arbeiten, ist es hilfreich, wenn sie eine ähnliche Definition von “1” haben. Das ermöglicht es den Teams, über die Größe zu diskutieren. Beispielsweise, wenn sie zusammen an einem gemeinsamen Backlog-Eintrag arbeiten oder wenn ein Team eine Story an ein anderes weitergibt.
Wenn jedes Team eine Story auswählt, für die es “einen halben Tag zum Entwickeln plus einen halben Tag zum Testen und Validieren” braucht, erreichen wir dieses Ziel. Ich bitte die Teams oft, zu prüfen, ob ihre “1”-Storys auch wirklich alle gleich groß sind.
Wenn das Verhältnis der Story Points nicht nur in einem Team, sondern teamübergreifend vereinbart wird, nennt man das in SAFe „aligned” bzw. “normalized”. Eine teamübergreifende Angleichung der Story Points (“aligned”) ist jedoch nicht notwendig. Es ist eine Möglichkeit, und oft gleichen sich die Story Points durch die Zusammenarbeit zwischen den Teams ohnehin an.

Nachdem wir mit einer Definition von “1” mit der Schätzung begonnen haben, werden alle geschätzten Product Backlog Einträge zu Referenzpunkten für weitere relative Schätzungen.
Wir müssen die “1” nur einmal im Leben eines Product Backlogs finden. Später, wenn wir mehr Product Backlog Einträge schätzen, gibt es eine Fülle von Product Backlog Einträgen mit Größenschätzungen. Diese können wir alle als Referenz verwenden. Es ist später völlig egal, wie wir die Referenzstory mit der Größe “1” ausgewählt haben.
Wir messen Velocity und prognostizieren Kapazität.
Am Ende jeder Timebox/Kadenz (z. B. Sprint/Iteration oder Planungsintervall/PI) können wir die Anzahl der Story Points aller Stories zählen, die in der Timebox fertiggestellt wurden. Diese Summe können wir mit der Timebox in Beziehung setzen: Diese Zahl wird Velocity genannt. Sie hilft uns, den Durchsatz bzw. unsere Geschwindigkeit zu verstehen.

Velocity ähnelt dem Throughput, der in Kanban-Systemen oft verwendet wird, um die pro Zeiteinheit gelieferten Elemente zu messen (siehe das Kanban Glossar oder den SAFe Measure and Grow Artikel). Im Gegensatz zum Throughput werden bei der Velocity die unterschiedlichen Größen der Einträge berücksichtigt.
Die Velocity (oder der Throughput) ändert sich im Laufe der Zeit, vor allem wenn sich ein Team verbessert.
Velocity ist nützlich, um eine Vorhersage darüber zu machen, wie viel wir in den nächsten Sprints/Iterationen schaffen können. Diese Vorhersage wird Capacity genannt. Sie hilft dabei, ein Sprint/Iteration Ziel zu formulieren und die Stories auszuwählen, die das Team im nächsten Sprint/der nächsten Iteration voraussichtlich liefern wird. Die zukünftige Velocity ist natürlich eine statistische Größe: Die Prognose ist eine Schätzung mit Varianz. Tina kann krank werden, die tatsächliche Größe der Story kann von der geschätzten Größe abweichen, und viele andere Dinge können passieren.
Nur bei einem neuen Team berechnen (“raten”) wir die anfängliche Kapazität.
Wenn ein Team neu ist, haben wir keine Daten. Daher können wir die Kapazität nicht vorhersagen. Es gibt mehrere Möglichkeiten, dies zu lösen. SAFe schlägt vor, die Kapazität für den ersten Sprint/die erste Iteration zu berechnen. SAFe nutzt 8 Story Points pro Entwickler für einen 2-wöchigen Sprint, oder allgemeiner 0,8 Story Points pro Arbeitstag.. 0,8 Story Points pro Arbeitstag berücksichtigen den Zeitaufwand für die Sprint-Events und das Refinement.
Eine andere Möglichkeit, die Kapazität für den ersten Sprint/die erste Iteration zu ermitteln, ist, dass das Team die Stories für den ersten Sprint auswählt und dann die Anzahl der Story Points zählt.
Beides ist möglich. Eigentlich ist das Vorgehen egal, denn wir machen das nur einmal im Leben eines Teams. Nach dem ersten Sprint messen wir die Geschwindigkeit und prognostizieren die Kapazität (siehe oben). Wir berechnen die Kapazität nur selten erneut.
Mit den Story Points und der Velocity können wir Liefertermine prognostizieren.
Stakeholder wollen oft wissen, wann eine Story abgeschlossen sein wird. Mit den Story Points und der Velocity können wir Prognosen für die Frage “wann wird es fertig” abgeben. Indem wir die Story Points mit der gemessenen Velocity multiplizieren, erhalten wir eine Prognose für die Zeit, die für die Fertigstellung dieser Story Points benötigt wird.
Wenn es zum Beispiel Product Backlog Einträge mit 100 SP gibt und wir eine aktuelle Velocity von 10 SP/Sprint haben, dann werden diese Einträge 10 Sprints benötigen. Natürlich nicht genau, denn die Zeit ist eine Schätzung mit einer Varianz und einem Konfidenzintervall. Diese Technik findet man in vielen Vergnügungsparks, wo an bestimmten Stellen der Warteschlange Schilder die Zeit angeben, die man ab diesem Punkt warten muss.
Die Vorhersage von Lieferterminen mithilfe von Story Points und Velocity hat zwei Vorteile. Erstens basiert das Lieferdatum auf Messungen und nicht auf Wünschen. Zweitens: Wenn sich die Geschwindigkeit ändert, folgen die Prognosen für die Liefertermine dieser Änderung.
Eine Sache, die bei diesen Prognosen zu beachten ist, ist, dass sich die Einträge und ihre Reihenfolge ändern: Product Backlogs sind emergent. Alle Prognosen beruhen auf dem aktuellen Stand der Unsicherheit. Bei Bedarf können wir diese Veränderung messen und in unsere Prognosen einbeziehen. Eine Vorhersage, die “nur” auf Velocity und Story Points basiert, ist jedoch ein wertvoller erster Schritt und für viele Unternehmen gut genug.

Story Points sind nicht für Vergleiche oder Vergütung gedacht.
Story Points helfen Teams dabei, Stories zu diskutieren, Empirie zu betreiben und Prognosen zu erstellen. Oft gibt es den Wunsch, die Leistung von Teams und Menschen zu messen und zu vergleichen. Dafür sind Story Points aber nicht gedacht.
Manche Organisationen benutzen Story Points, um Teams zu bezahlen. Auch dafür sind Story Points nicht gedacht. Die Bezahlung nach Story Points lenkt – genau wie die Zahlung von Prämien – die Teams von ihren Zielen ab (siehe die Studie “Large Stakes and Big Mistakes” der Federal Reserve Bank of Boston).
Ein Team kann nicht aufhören, Story Points mit dem Aufwand in Verbindung zu bringen? Verwendet T-Shirt-Größen.
Oft verheddern sich Teams bei der Schätzung mit Story Points: Sie setzen Story Points mit einem festen Arbeitsaufwand gleich, oder es fällt ihnen schwer Schätzungen als eine Verteilung (“irgendwas um 13”) zu verstehen und nicht als eine Zahl.
Wenn das passiert, verwende ich T-Shirt-Größen (XXS bis XXL). Oft ist es nötig, mit den Größenschätzungen noch Berechnungen zu machen, z. B. Geschwindigkeitsmessungen, Lieferterminvorhersagen oder Kapazitätsvorhersagen. Das kann man tun, indem man eine Beziehung zwischen den T-Shirt-Größen herstellt und jede T-Shirt-Größe einer Story Point-Zahl zuordnet.
Falls sich ein Team mit Schätzungen nicht anfreunden kann, funktionieren auch ähnliche groß geschnittene Stories und die Verwendung von Throughput. Damit sind Prognosen genauso gut wie mit Velocity und Story Points möglich.
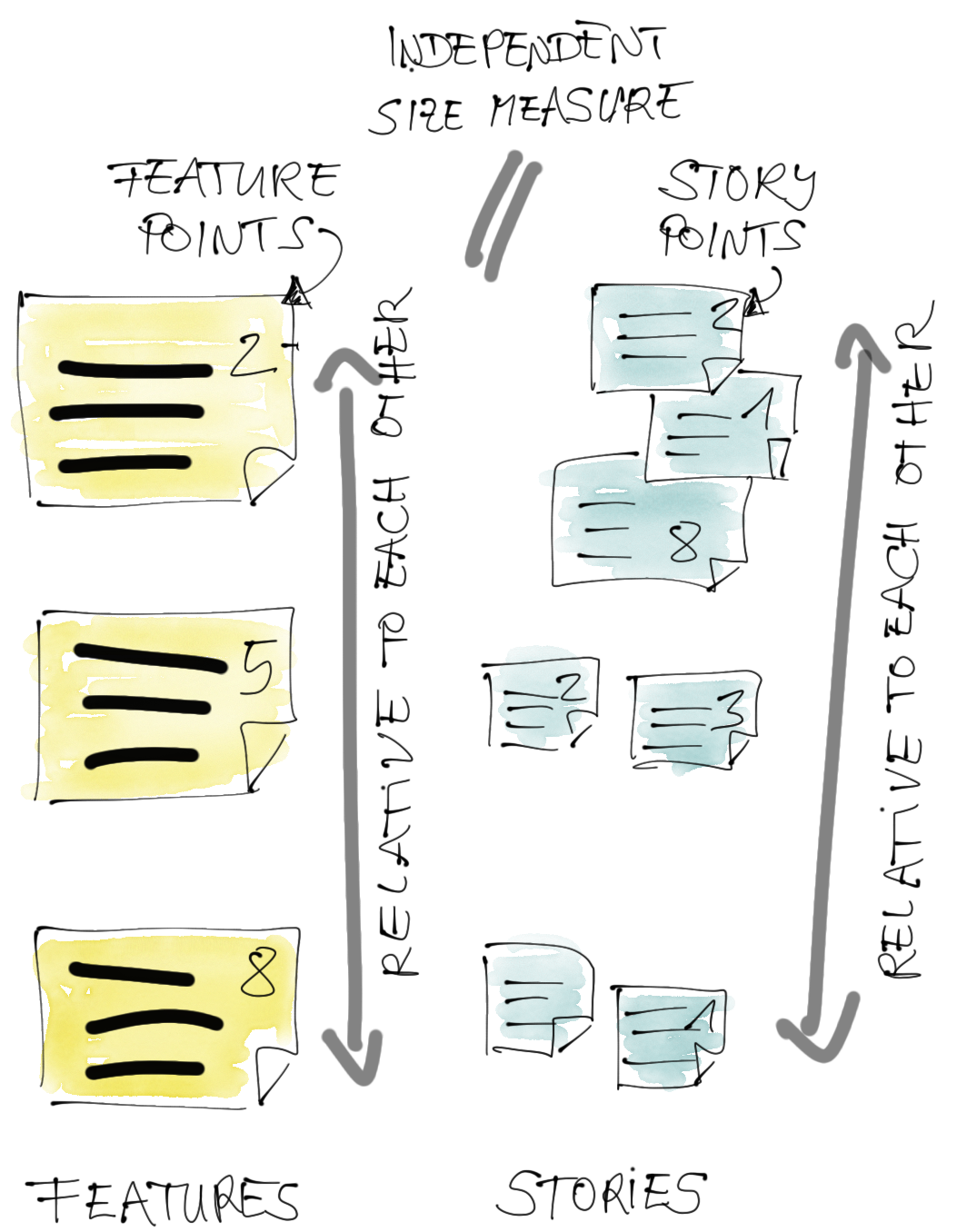
Features können ihre eigene relative Größe haben.
Für Features im ART Backlog gilt all das, was wir zuvor gesagt haben, genauso. Wir schätzen die Größe relativ. Wir messen die Velocity und prognostizieren die Kapazität für eine Timebox, in diesem Fall für ein Planungsintervall (PI).
Eine Möglichkeit ist, Feature Points als unabhängige Größeneinheit für Features zu verwenden. Feature Points funktionieren auf die gleiche Weise wie Story Points, nur auf der höheren Ebene von Features. Feature Points haben keinen direkten Bezug zu Story Points, so wie Story Points keinen direkten Bezug zu Zeit haben.
Eine andere Möglichkeit ist, die Größe der Features auch in Story Points zu schätzen. In diesem Fall gibt es nicht nur eine Beziehung zwischen Stories, sondern auch zwischen Features und Stories. Wenn ihr Story Points für Features verwenden wollt, müssen die Story Points zwischen den Teams angeglichen („aligned“) sein. Außerdem sind “große” Story Points wie 100, 200, usw. nötig. SAFe beschreibt beide Möglichkeiten. Letztlich ist es eure Entscheidung. Ich persönlich bevorzuge Feature Points, um die Dinge lose zu koppeln.
Größenschätzungen für Features sollten von Teamvertretern vorgenommen werden. SAFe schlägt dies auch vor. Auch wenn Product Owner vom Standpunkt der Skalierung aus gesehen Teamvertreter sind (Product Owner sind Teil vom Scrum Team), so habe ich persönlich gerne auch Entwickler im Raum, wenn wir die Größe von Features schätzen.
Ändert beim Skalieren nichts am Konzept der Story Points.
Lange Rede, kurzer Sinn: Das Konzept der Story Points ist alt, und mit SAFe ändern wir das Konzept nicht. Also: Wenn es so aussieht, als ob plötzlich etwas ganz anders ist, ist wahrscheinlich irgendetwas falsch.
Danke, liebe Rezensenten.
Schätzungen sind ein schwieriges Thema. Ich danke meinen vielen Reviewern, die diesen Blogartikel erheblich verbessert haben: David Croome, Tina Behers, Alexander Post, Simon Porro und Michele Lanzinger.
Willst du mehr wissen? Dann komm zu einem unserer Trainings.
Wir besprechen diese Themen in unserem Leading SAFe Training oder in unserem Implementing SAFe Training. Erlebe ein Training mit vielen praktischen Aktivitäten, guten Diskussionen und erfahrenen Experten. Triff die Leute mit den großer praktischer Erfahrung in Scaled Agile und Business Agility.
Lies meinen anderen Artikel über SAFe Schätzen
SAFe und Scaled Agile Framework sind eingetragene Marken von Scaled Agile, Inc.